
Искусственный интеллект, нейронные сети, машинное обучение — что на самом деле означают все эти нынче популярные понятия? Для большинства непосвященных людей, коим и являюсь я сам, они всегда казались чем-то фантастическим, но на самом деле суть их лежит на поверхности. У меня давно созревала идея написать простым языком об искусственных нейронных сетях. Узнать самому и рассказать другим, что представляют собой эта технология, как она работают, рассмотреть ее историю и перспективы. В этой статье я постарался не залезать в дебри, а просто и популярно рассказать об этом перспективном направление в мире высоких технологий.

Искусственный интеллект, нейронные сети, машинное обучение - что на самом деле означают все эти нынче популярные понятия? Для большинства непосвященных людей, коим являюсь и я сам, они всегда казались чем-то фантастическим, но на самом деле суть их лежит на поверхности. У меня давно созревала идея написать простым языком об искусственных нейронных сетях. Узнать самому и рассказать другим, что представляет собой эта технология, как она работает, рассмотреть ее историю и перспективы. В этой статье я постарался не залезать в дебри, а просто и популярно рассказать об этом перспективном направление в мире высоких технологий.
Немного истории
Впервые понятие искусственных нейронных сетей (ИНС) возникло при попытке смоделировать процессы головного мозга. Первым серьезным прорывом в этой сфере можно считать создание модели нейронных сетей МакКаллока-Питтса в 1943 году. Учеными впервые была разработана модель искусственного нейрона. Ими также была предложена конструкция сети из этих элементов для выполнения логических операций. Но самое главное, учеными было доказано, что подобная сеть способна обучаться.

Следующим важным шагом стала разработка Дональдом Хеббом первого алгоритма вычисления ИНС в 1949 году, который стал основополагающем на несколько последующих десятилетий. В 1958 году Фрэнком Розенблаттом был разработан парцептрон - система, имитирующая процессы головного мозга. В свое время технология не имела аналогов и до сих пор является основополагающей в нейронных сетях. В 1986 году практически одновременно, независимо друг от друга американскими и советскими учеными был существенно доработан основополагающий метод обучения многослойного перцептрона . В 2007 году нейронные сети перенесли второе рождение. Британский информатик Джеффри Хинтоном впервые разработал алгоритм глубокого обучения многослойных нейронных сетей, который сейчас, например, используется для работы беспилотных автомобилей.
Коротко о главном
В общем смысле слова, нейронные сети - это математические модели, работающие по принципу сетей нервных клеток животного организма. ИНС могут быть реализованы как в программируемые, так и в аппаратные решения. Для простоты восприятия нейрон можно представить, как некую ячейку, у которой имеется множество входных отверстий и одно выходное. Каким образом многочисленные входящие сигналы формируются в выходящий, как раз и определяет алгоритм вычисления. На каждый вход нейрона подаются действенные значения, которые затем распространяются по межнейронным связям (синопсисам). У синапсов есть один параметр - вес, благодаря которому входная информация изменяется при переходе от одного нейрона к другому. Легче всего принцип работы нейросетей можно представить на примере смешения цветов. Синий, зеленый и красный нейрон имеют разные веса. Информация того нейрона, вес которого больше будет доминирующей в следующем нейроне.

Сама нейросеть представляет собой систему из множества таких нейронов (процессоров). По отдельности эти процессоры достаточно просты (намного проще, чем процессор персонального компьютера), но будучи соединенными в большую систему нейроны способны выполнять очень сложные задачи.
В зависимости от области применения нейросеть можно трактовать по-разному, Например, с точки зрения машинного обучения ИНС представляет собой метод распознавания образов. С математической точки зрения - это многопараметрическая задача. С точки зрения кибернетики - модель адаптивного управления робототехникой. Для искусственного интеллекта ИНС - это основополагающее составляющее для моделирования естественного интеллекта с помощью вычислительных алгоритмов.
Основным преимуществом нейросетей над обычными алгоритмами вычисления является их возможность обучения. В общем смысле слова обучение заключается в нахождении верных коэффициентов связи между нейронами, а также в обобщении данных и выявлении сложных зависимостей между входными и выходными сигналами. Фактически, удачное обучение нейросети означает, что система будет способна выявить верный результат на основании данных, отсутствующих в обучающей выборке.

Сегодняшнее положение
И какой бы многообещающей не была бы эта технология, пока что ИНС еще очень далеки от возможностей человеческого мозга и мышления. Тем не менее, уже сейчас нейросети применяются во многих сферах деятельности человека. Пока что они не способны принимать высокоинтеллектуальные решения, но в состоянии заменить человека там, где раньше он был необходим. Среди многочисленных областей применения ИНС можно отметить: создание самообучающихся систем производственных процессов, беспилотные транспортные средства, системы распознавания изображений, интеллектуальные охранные системы, робототехника, системы мониторинга качества, голосовые интерфейсы взаимодействия, системы аналитики и многое другое. Такое широкое распространение нейросетей помимо прочего обусловлено появлением различных способов ускорения обучения ИНС.

На сегодняшний день рынок нейронных сетей огромен - это миллиарды и миллиарды долларов. Как показывает практика, большинство технологий нейросетей по всему миру мало отличаются друг от друга. Однако применение нейросетей - это очень затратное занятие, которое в большинстве случаев могут позволить себе только крупные компании. Для разработки, обучения и тестирования нейронных сетей требуются большие вычислительные мощности, очевидно, что этого в достатке имеется у крупных игроков на рынке ИТ. Среди основных компаний, ведущих разработки в этой области можно отметить подразделение Google DeepMind, подразделение Microsoft Research, компании IBM, Facebook и Baidu.
Конечно, все это хорошо: нейросети развиваются, рынок растет, но пока что главная задача так и не решена. Человечеству не удалось создать технологию, хотя бы приближенную по возможностям к человеческому мозгу. Давайте рассмотрим основные различия между человеческим мозгом и искусственными нейросетями.
Почему нейросети еще далеки до человеческого мозга?
Самым главным отличием, которое в корне меняет принцип и эффективность работы системы - это разная передача сигналов в искусственных нейронных сетях и в биологической сети нейронов. Дело в том, что в ИНС нейроны передают значения, которые являются действительными значениями, то есть числами. В человеческом мозге осуществляется передача импульсов с фиксированной амплитудой, причем эти импульсы практически мгновенные. Отсюда вытекает целый ряд преимуществ человеческой сети нейронов.

Во-первых, линии связи в мозге намного эффективнее и экономичнее, чем в ИНС. Во-вторых, импульсная схема обеспечивает простоту реализации технологии: достаточно использование аналоговых схем вместо сложных вычислительных механизмов. В конечном счете, импульсные сети защищены от звуковых помех. Действенные числа подвержены влиянию шумов, в результате чего повышается вероятность возникновения ошибки.
Итог
Безусловно, в последнее десятилетие произошел настоящий бум развития нейронных сетей. В первую очередь это связано с тем, что процесс обучения ИНС стал намного быстрее и проще. Также стали активно разрабатываться так называемые «предобученные» нейросети, которые позволяют существенно ускорить процесс внедрения технологии. И если пока что рано говорить о том, смогут ли когда-то нейросети полностью воспроизвести возможности человеческого мозга, вероятность того, что в ближайшее десятилетие ИНС смогут заменить человека на четверти существующих профессий все больше становится похожим на правду.
Для тех, кто хочет знать больше
- Большая нейронная война: что на самом деле затевает Google
- Как когнитивные компьютеры могут изменить наше будущее
Добрый день, меня зовут Наталия Ефремова, и я research scientist в компании NtechLab. Сегодня я буду рассказывать про виды нейронных сетей и их применение.
Сначала скажу пару слов о нашей компании. Компания новая, может быть многие из вас еще не знают, чем мы занимаемся. В прошлом году мы выиграли состязание MegaFace . Это международное состязание по распознаванию лиц. В этом же году была открыта наша компания, то есть мы на рынке уже около года, даже чуть больше. Соответственно, мы одна из лидирующих компаний в распознавании лиц и обработке биометрических изображений.
Первая часть моего доклада будет направлена тем, кто незнаком с нейронными сетями. Я занимаюсь непосредственно deep learning. В этой области я работаю более 10 лет. Хотя она появилась чуть меньше, чем десятилетие назад, раньше были некие зачатки нейронных сетей, которые были похожи на систему deep learning.
В последние 10 лет deep learning и компьютерное зрение развивались неимоверными темпами. Все, что сделано значимого в этой области, произошло в последние лет 6.
Я расскажу о практических аспектах: где, когда, что применять в плане deep learning для обработки изображений и видео, для распознавания образов и лиц, поскольку я работаю в компании, которая этим занимается. Немножко расскажу про распознавание эмоций, какие подходы используются в играх и робототехнике. Также я расскажу про нестандартное применение deep learning, то, что только выходит из научных институтов и пока что еще мало применяется на практике, как это может применяться, и почему это сложно применить.
Доклад будет состоять из двух частей. Так как большинство знакомы с нейронными сетями, сначала я быстро расскажу, как работают нейронные сети, что такое биологические нейронные сети, почему нам важно знать, как это работает, что такое искусственные нейронные сети, и какие архитектуры в каких областях применяются.
Сразу извиняюсь, я буду немного перескакивать на английскую терминологию, потому что большую часть того, как называется это на русском языке, я даже не знаю. Возможно вы тоже.
Итак, первая часть доклада будет посвящена сверточным нейронным сетям. Я расскажу, как работают convolutional neural network (CNN), распознавание изображений на примере из распознавания лиц. Немного расскажу про рекуррентные нейронные сети recurrent neural network (RNN) и обучение с подкреплением на примере систем deep learning.
В качестве нестандартного применения нейронных сетей я расскажу о том, как CNN работает в медицине для распознавания воксельных изображений, как используются нейронные сети для распознавания бедности в Африке.
Что такое нейронные сети
Прототипом для создания нейронных сетей послужили, как это ни странно, биологические нейронные сети. Возможно, многие из вас знают, как программировать нейронную сеть, но откуда она взялась, я думаю, некоторые не знают. Две трети всей сенсорной информации, которая к нам попадает, приходит с зрительных органов восприятия. Более одной трети поверхности нашего мозга заняты двумя самыми главными зрительными зонами - дорсальный зрительный путь и вентральный зрительный путь.Дорсальный зрительный путь начинается в первичной зрительной зоне, в нашем темечке и продолжается наверх, в то время как вентральный путь начинается на нашем затылке и заканчивается примерно за ушами. Все важное распознавание образов, которое у нас происходит, все смыслонесущее, то что мы осознаём, проходит именно там же, за ушами.
Почему это важно? Потому что часто нужно для понимания нейронных сетей. Во-первых, все об этом рассказывают, и я уже привыкла что так происходит, а во-вторых, дело в том, что все области, которые используются в нейронных сетях для распознавания образов, пришли к нам именно из вентрального зрительного пути, где каждая маленькая зона отвечает за свою строго определенную функцию.
Изображение попадает к нам из сетчатки глаза, проходит череду зрительных зон и заканчивается в височной зоне.
В далекие 60-е годы прошлого века, когда только начиналось изучение зрительных зон мозга, первые эксперименты проводились на животных, потому что не было fMRI. Исследовали мозг с помощью электродов, вживлённых в различные зрительные зоны.
Первая зрительная зона была исследована Дэвидом Хьюбелем и Торстеном Визелем в 1962 году. Они проводили эксперименты на кошках. Кошкам показывались различные движущиеся объекты. На что реагировали клетки мозга, то и было тем стимулом, которое распознавало животное. Даже сейчас многие эксперименты проводятся этими драконовскими способами. Но тем не менее это самый эффективный способ узнать, что делает каждая мельчайшая клеточка в нашем мозгу.
Таким же способом были открыты еще многие важные свойства зрительных зон, которые мы используем в deep learning сейчас. Одно из важнейших свойств - это увеличение рецептивных полей наших клеток по мере продвижения от первичных зрительных зон к височным долям, то есть более поздним зрительным зонам. Рецептивное поле - это та часть изображения, которую обрабатывает каждая клеточка нашего мозга. У каждой клетки своё рецептивное поле. Это же свойство сохраняется и в нейронных сетях, как вы, наверное, все знаете.
Также с возрастанием рецептивных полей увеличиваются сложные стимулы, которые обычно распознают нейронные сети.

Здесь вы видите примеры сложности стимулов, различных двухмерных форм, которые распознаются в зонах V2, V4 и различных частях височных полей у макак. Также проводятся некоторое количество экспериментов на МРТ.

Здесь вы видите, как проводятся такие эксперименты. Это 1 нанометровая часть зон IT cortex"a мартышки при распознавании различных объектов. Подсвечено то, где распознается.
Просуммируем. Важное свойство, которое мы хотим перенять у зрительных зон - это то, что возрастают размеры рецептивных полей, и увеличивается сложность объектов, которые мы распознаем.
Компьютерное зрение
До того, как мы научились это применять к компьютерному зрению - в общем, как такового его не было. Во всяком случае, оно работало не так хорошо, как работает сейчас.Все эти свойства мы переносим в нейронную сеть, и вот оно заработало, если не включать небольшое отступление к датасетам, о котором расскажу попозже.
Но сначала немного о простейшем перцептроне. Он также образован по образу и подобию нашего мозга. Простейший элемент напоминающий клетку мозга - нейрон. Имеет входные элементы, которые по умолчанию располагаются слева направо, изредка снизу вверх. Слева это входные части нейрона, справа выходные части нейрона.
Простейший перцептрон способен выполнять только самые простые операции. Для того, чтобы выполнять более сложные вычисления, нам нужна структура с большим количеством скрытых слоёв.

В случае компьютерного зрения нам нужно еще больше скрытых слоёв. И только тогда система будет осмысленно распознавать то, что она видит.
Итак, что происходит при распознавании изображения, я расскажу на примере лиц.
Для нас посмотреть на эту картинку и сказать, что на ней изображено именно лицо статуи, достаточно просто. Однако до 2010 года для компьютерного зрения это было невероятно сложной задачей. Те, кто занимался этим вопросом до этого времени, наверное, знают насколько тяжело было описать объект, который мы хотим найти на картинке без слов.
Нам нужно это было сделать каким-то геометрическим способом, описать объект, описать взаимосвязи объекта, как могут эти части относиться к друг другу, потом найти это изображение на объекте, сравнить их и получить, что мы распознали плохо. Обычно это было чуть лучше, чем подбрасывание монетки. Чуть лучше, чем chance level.
Сейчас это происходит не так. Мы разбиваем наше изображение либо на пиксели, либо на некие патчи: 2х2, 3х3, 5х5, 11х11 пикселей - как удобно создателям системы, в которой они служат входным слоем в нейронную сеть.
Сигналы с этих входных слоёв передаются от слоя к слою с помощью синапсов, каждый из слоёв имеет свои определенные коэффициенты. Итак, мы передаём от слоя к слою, от слоя к слою, пока мы не получим, что мы распознали лицо.
Условно все эти части можно разделить на три класса, мы их обозначим X, W и Y, где Х - это наше входное изображение, Y - это набор лейблов, и нам нужно получить наши веса. Как мы вычислим W?
При наличии нашего Х и Y это, кажется, просто. Однако то, что обозначено звездочкой, очень сложная нелинейная операция, которая, к сожалению, не имеет обратной. Даже имея 2 заданных компоненты уравнения, очень сложно ее вычислить. Поэтому нам нужно постепенно, методом проб и ошибок, подбором веса W сделать так, чтобы ошибка максимально уменьшилась, желательно, чтобы стала равной нулю.

Этот процесс происходит итеративно, мы постоянно уменьшаем, пока не находим то значение веса W, которое нас достаточно устроит.
К слову, ни одна нейронная сеть, с которой я работала, не достигала ошибки, равной нулю, но работала при этом достаточно хорошо.

Перед вами первая сеть, которая победила на международном соревновании ImageNet в 2012 году. Это так называемый AlexNet. Это сеть, которая впервые заявила о себе, о том, что существует convolutional neural networks и с тех самых пор на всех международных состязаниях уже convolutional neural nets не сдавали своих позиций никогда.
Несмотря на то, что эта сеть достаточно мелкая (в ней всего 7 скрытых слоёв), она содержит 650 тысяч нейронов с 60 миллионами параметров. Для того, чтобы итеративно научиться находить нужные веса, нам нужно очень много примеров.
Нейронная сеть учится на примере картинки и лейбла. Как нас в детстве учат «это кошка, а это собака», так же нейронные сети обучаются на большом количестве картинок. Но дело в том, что до 2010 не существовало достаточно большого data set’a, который способен был бы научить такое количество параметров распознавать изображения.
Самые большие базы данных, которые существовали до этого времени: PASCAL VOC, в который было всего 20 категорий объектов, и Caltech 101, который был разработан в California Institute of Technology. В последнем была 101 категория, и это было много. Тем же, кто не сумел найти свои объекты ни в одной из этих баз данных, приходилось стоить свои базы данных, что, я скажу, страшно мучительно.
Однако, в 2010 году появилась база ImageNet, в которой было 15 миллионов изображений, разделённые на 22 тысячи категорий. Это решило нашу проблему обучения нейронных сетей. Сейчас все желающие, у кого есть какой-либо академический адрес, могут спокойно зайти на сайт базы, запросить доступ и получить эту базу для тренировки своих нейронных сетей. Они отвечают достаточно быстро, по-моему, на следующий день.
По сравнению с предыдущими data set’ами, это очень большая база данных.

На примере видно, насколько было незначительно все то, что было до неё. Одновременно с базой ImageNet появилось соревнование ImageNet, международный challenge, в котором все команды, желающие посоревноваться, могут принять участие.
В этом году победила сеть, созданная в Китае, в ней было 269 слоёв. Не знаю, сколько параметров, подозреваю, тоже много.
Архитектура глубинной нейронной сети
Условно ее можно разделить на 2 части: те, которые учатся, и те, которые не учатся.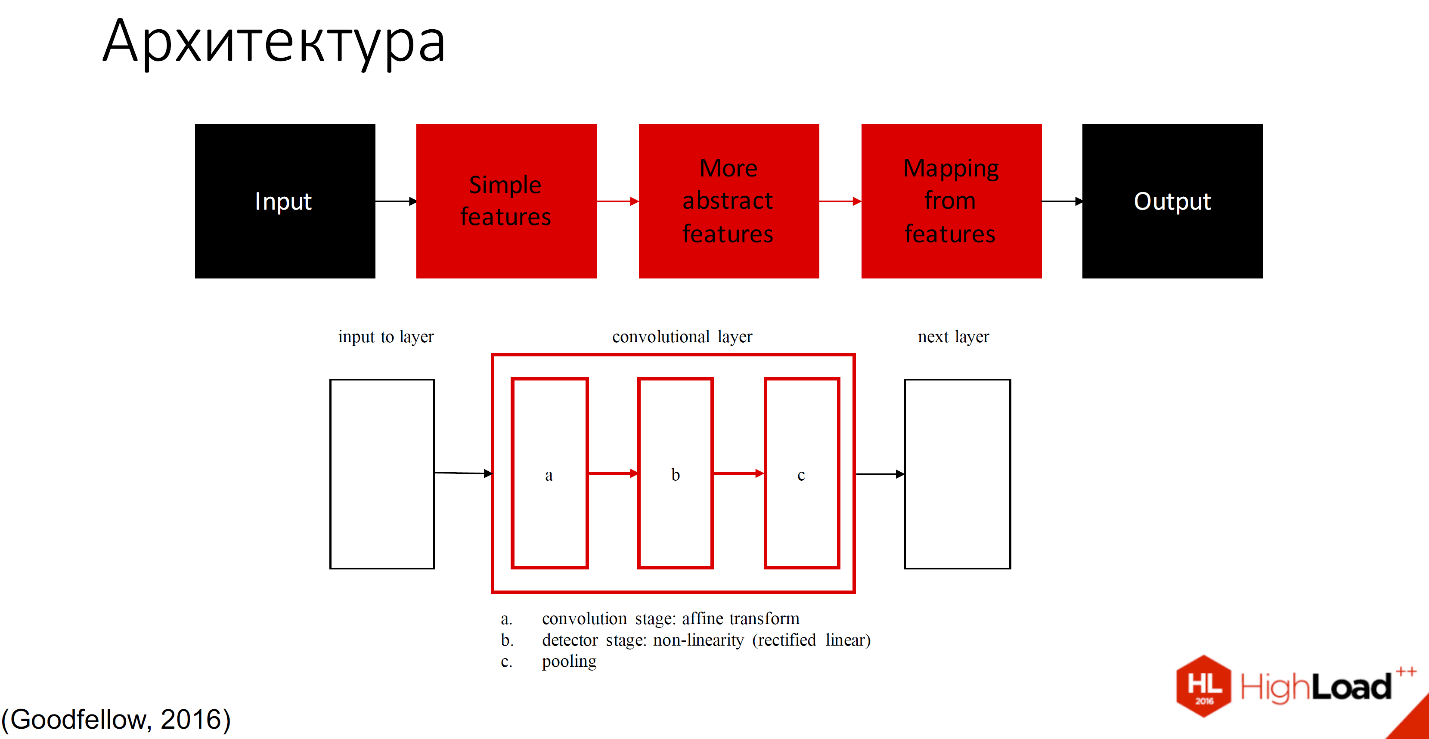
Чёрным обозначены те части, которые не учатся, все остальные слои способны обучаться. Существует множество определений того, что находится внутри каждого сверточного слоя. Одно из принятых обозначений - один слой с тремя компонентами разделяют на convolution stage, detector stage и pooling stage.
Не буду вдаваться в детали, еще будет много докладов, в которых подробно рассмотрено, как это работает. Расскажу на примере.
Поскольку организаторы просили меня не упоминать много формул, я их выкинула совсем.

Итак, входное изображение попадает в сеть слоёв, которые можно назвать фильтрами разного размера и разной сложности элементов, которые они распознают. Эти фильтры составляют некий свой индекс или набор признаков, который потом попадает в классификатор. Обычно это либо SVM, либо MLP - многослойный перцептрон, кому что удобно.
По образу и подобию с биологической нейронной сетью объекты распознаются разной сложности. По мере увеличения количества слоёв это все потеряло связь с cortex’ом, поскольку там ограничено количество зон в нейронной сети. 269 или много-много зон абстракции, поэтому сохраняется только увеличение сложности, количества элементов и рецептивных полей.

Если рассмотреть на примере распознавания лиц, то у нас рецептивное поле первого слоя будет маленьким, потом чуть побольше, побольше, и так до тех пор, пока наконец мы не сможем распознавать уже лицо целиком.

С точки зрения того, что находится у нас внутри фильтров, сначала будут наклонные палочки плюс немного цвета, затем части лиц, а потом уже целиком лица будут распознаваться каждой клеточкой слоя.
Есть люди, которые утверждают, что человек всегда распознаёт лучше, чем сеть. Так ли это?
В 2014 году ученые решили проверить, насколько мы хорошо распознаем в сравнении с нейронными сетями. Они взяли 2 самые лучшие на данный момент сети - это AlexNet и сеть Мэттью Зиллера и Фергюса, и сравнили с откликом разных зон мозга макаки, которая тоже была научена распознавать какие-то объекты. Объекты были из животного мира, чтобы обезьяна не запуталась, и были проведены эксперименты, кто же распознаёт лучше.
Так как получить отклик от мартышки внятно невозможно, ей вживили электроды и мерили непосредственно отклик каждого нейрона.
Оказалось, что в нормальных условиях клетки мозга реагировали так же хорошо, как и state of the art model на тот момент, то есть сеть Мэттью Зиллера.
Однако при увеличении скорости показа объектов, увеличении количества шумов и объектов на изображении скорость распознавания и его качество нашего мозга и мозга приматов сильно падают. Даже самая простая сверточная нейронная сеть распознаёт объекты лучше. То есть официально нейронные сети работают лучше, чем наш мозг.
Классические задачи сверточных нейронных сетей
Их на самом деле не так много, они относятся к трём классам. Среди них - такие задачи, как идентификация объекта, семантическая сегментация, распознавание лиц, распознавание частей тела человека, семантическое определение границ, выделение объектов внимания на изображении и выделение нормалей к поверхности. Их условно можно разделить на 3 уровня: от самых низкоуровневых задач до самых высокоуровневых задач.
На примере этого изображения рассмотрим, что делает каждая из задач.
- Определение границ - это самая низкоуровневая задача, для которой уже классически применяются сверточные нейронные сети.
- Определение вектора к нормали позволяет нам реконструировать трёхмерное изображение из двухмерного.
- Saliency, определение объектов внимания - это то, на что обратил бы внимание человек при рассмотрении этой картинки.
- Семантическая сегментация позволяет разделить объекты на классы по их структуре, ничего не зная об этих объектах, то есть еще до их распознавания.
- Семантическое выделение границ - это выделение границ, разбитых на классы.
- Выделение частей тела человека .
- И самая высокоуровневая задача - распознавание самих объектов , которое мы сейчас рассмотрим на примере распознавания лиц.
Распознавание лиц
Первое, что мы делаем - пробегаем face detector"ом по изображению для того, чтобы найти лицо. Далее мы нормализуем, центрируем лицо и запускаем его на обработку в нейронную сеть. После чего получаем набор или вектор признаков однозначно описывающий фичи этого лица.
Затем мы можем этот вектор признаков сравнить со всеми векторами признаков, которые хранятся у нас в базе данных, и получить отсылку на конкретного человека, на его имя, на его профиль - всё, что у нас может храниться в базе данных.
Именно таким образом работает наш продукт FindFace - это бесплатный сервис, который помогает искать профили людей в базе «ВКонтакте».
Кроме того, у нас есть API для компаний, которые хотят попробовать наши продукты. Мы предоставляем сервис по детектированию лиц, по верификации и по идентификации пользователей.
Сейчас у нас разработаны 2 сценария. Первый - это идентификация, поиск лица по базе данных. Второе - это верификация, это сравнение двух изображений с некой вероятностью, что это один и тот же человек. Кроме того, у нас сейчас в разработке распознавание эмоций, распознавание изображений на видео и liveness detection - это понимание, живой ли человек перед камерой или фотография.
Немного статистики. При идентификации, при поиске по 10 тысячам фото у нас точность около 95% в зависимости от качества базы, 99% точность верификации. И помимо этого данный алгоритм очень устойчив к изменениям - нам необязательно смотреть в камеру, у нас могут быть некие загораживающие предметы: очки, солнечные очки, борода, медицинская маска. В некоторых случаях мы можем победить даже такие невероятные сложности для компьютерного зрения, как и очки, и маска.
Очень быстрый поиск, затрачивается 0,5 секунд на обработку 1 миллиарда фотографий. Нами разработан уникальный индекс быстрого поиска. Также мы можем работать с изображениями низкого качества, полученных с CCTV-камер. Мы можем обрабатывать это все в режиме реального времени. Можно загружать фото через веб-интерфейс, через Android, iOS и производить поиск по 100 миллионам пользователей и их 250 миллионам фотографий.
Как я уже говорила мы заняли первое место на MegaFace competition - аналог для ImageNet, но для распознавания лиц. Он проводится уже несколько лет, в прошлом году мы были лучшими среди 100 команд со всего мира, включая Google.
Рекуррентные нейронные сети
Recurrent neural networks мы используем тогда, когда нам недостаточно распознавать только изображение. В тех случаях, когда нам важно соблюдать последовательность, нам нужен порядок того, что у нас происходит, мы используем обычные рекуррентные нейронные сети.Это применяется для распознавания естественного языка, для обработки видео, даже используется для распознавания изображений.
Про распознавание естественного языка я рассказывать не буду - после моего доклада еще будут два, которые будут направлены на распознавание естественного языка. Поэтому я расскажу про работу рекуррентных сетей на примере распознавания эмоций.
Что такое рекуррентные нейронные сети? Это примерно то же самое, что и обычные нейронные сети, но с обратной связью. Обратная связь нам нужна, чтобы передавать на вход нейронной сети или на какой-то из ее слоев предыдущее состояние системы.
Предположим, мы обрабатываем эмоции. Даже в улыбке - одной из самых простых эмоций - есть несколько моментов: от нейтрального выражения лица до того момента, когда у нас будет полная улыбка. Они идут друг за другом последовательно. Чтоб это хорошо понимать, нам нужно уметь наблюдать за тем, как это происходит, передавать то, что было на предыдущем кадре в следующий шаг работы системы.

В 2005 году на состязании Emotion Recognition in the Wild специально для распознавания эмоций команда из Монреаля представила рекуррентную систему, которая выглядела очень просто. У нее было всего несколько свёрточных слоев, и она работала исключительно с видео. В этом году они добавили также распознавание аудио и cагрегировали покадровые данные, которые получаются из convolutional neural networks, данные аудиосигнала с работой рекуррентной нейронной сети (с возвратом состояния) и получили первое место на состязании.
Обучение с подкреплением
Следующий тип нейронных сетей, который очень часто используется в последнее время, но не получил такой широкой огласки, как предыдущие 2 типа - это deep reinforcement learning, обучение с подкреплением.Дело в том, что в предыдущих двух случаях мы используем базы данных. У нас есть либо данные с лиц, либо данные с картинок, либо данные с эмоциями с видеороликов. Если у нас этого нет, если мы не можем это отснять, как научить робота брать объекты? Это мы делаем автоматически - мы не знаем, как это работает. Другой пример: составлять большие базы данных в компьютерных играх сложно, да и не нужно, можно сделать гораздо проще.
Все, наверное, слышали про успехи deep reinforcement learning в Atari и в го.
Кто слышал про Atari? Ну кто-то слышал, хорошо. Про AlphaGo думаю слышали все, поэтому я даже не буду рассказывать, что конкретно там происходит.

Что происходит в Atari? Слева как раз изображена архитектура этой нейронной сети. Она обучается, играя сама с собой для того, чтобы получить максимальное вознаграждение. Максимальное вознаграждение - это максимально быстрый исход игры с максимально большим счетом.
Справа вверху - последний слой нейронной сети, который изображает всё количество состояний системы, которая играла сама против себя всего лишь в течение двух часов. Красным изображены желательные исходы игры с максимальным вознаграждением, а голубым - нежелательные. Сеть строит некое поле и движется по своим обученным слоям в то состояние, которого ей хочется достичь.
В робототехнике ситуация состоит немного по-другому. Почему? Здесь у нас есть несколько сложностей. Во-первых, у нас не так много баз данных. Во-вторых, нам нужно координировать сразу три системы: восприятие робота, его действия с помощью манипуляторов и его память - то, что было сделано в предыдущем шаге и как это было сделано. В общем это все очень сложно.
Дело в том, что ни одна нейронная сеть, даже deep learning на данный момент, не может справится с этой задачей достаточно эффективно, поэтому deep learning только исключительно кусочки того, что нужно сделать роботам. Например, недавно Сергей Левин предоставил систему, которая учит робота хватать объекты.

Вот здесь показаны опыты, которые он проводил на своих 14 роботах-манипуляторах.
Что здесь происходит? В этих тазиках, которые вы перед собой видите, различные объекты: ручки, ластики, кружки поменьше и побольше, тряпочки, разные текстуры, разной жесткости. Неясно, как научить робота захватывать их. В течение многих часов, а даже, вроде, недель, роботы тренировались, чтобы уметь захватывать эти предметы, составлялись по этому поводу базы данных.
Базы данных - это некий отклик среды, который нам нужно накопить для того, чтобы иметь возможность обучить робота что-то делать в дальнейшем. В дальнейшем роботы будут обучаться на этом множестве состояний системы.
Нестандартные применения нейронных сетей
Это к сожалению, конец, у меня не много времени. Я расскажу про те нестандартные решения, которые сейчас есть и которые, по многим прогнозам, будут иметь некое приложение в будущем.Итак, ученые Стэнфорда недавно придумали очень необычное применение нейронной сети CNN для предсказания бедности. Что они сделали?
На самом деле концепция очень проста. Дело в том, что в Африке уровень бедности зашкаливает за все мыслимые и немыслимые пределы. У них нет даже возможности собирать социальные демографические данные. Поэтому с 2005 года у нас вообще нет никаких данных о том, что там происходит.
Учёные собирали дневные и ночные карты со спутников и скармливали их нейронной сети в течение некоторого времени.
Нейронная сеть была преднастроена на ImageNet"е. То есть первые слои фильтров были настроены так, чтобы она умела распознавать уже какие-то совсем простые вещи, например, крыши домов, для поиска поселения на дневных картах. Затем дневные карты были сопоставлены с картами ночной освещенности того же участка поверхности для того, чтобы сказать, насколько есть деньги у населения, чтобы хотя бы освещать свои дома в течение ночного времени.

Здесь вы видите результаты прогноза, построенного нейронной сетью. Прогноз был сделан с различным разрешением. И вы видите - самый последний кадр - реальные данные, собранные правительством Уганды в 2005 году.
Можно заметить, что нейронная сеть составила достаточно точный прогноз, даже с небольшим сдвигом с 2005 года.
Были конечно и побочные эффекты. Ученые, которые занимаются deep learning, всегда с удивлением обнаруживают разные побочные эффекты. Например, как те, что сеть научилась распознавать воду, леса, крупные строительные объекты, дороги - все это без учителей, без заранее построенных баз данных. Вообще полностью самостоятельно. Были некие слои, которые реагировали, например, на дороги.
И последнее применение о котором я хотела бы поговорить - семантическая сегментация 3D изображений в медицине. Вообще medical imaging - это сложная область, с которой очень сложно работать.
Для этого есть несколько причин.
- У нас очень мало баз данных. Не так легко найти картинку мозга, к тому же повреждённого, и взять ее тоже ниоткуда нельзя.
- Даже если у нас есть такая картинка, нужно взять медика и заставить его вручную размещать все многослойные изображения, что очень долго и крайне неэффективно. Не все медики имеют ресурсы для того, чтобы этим заниматься.
- Нужна очень высокая точность. Медицинская система не может ошибаться. При распознавании, например, котиков, не распознали - ничего страшного. А если мы не распознали опухоль, то это уже не очень хорошо. Здесь особо свирепые требования к надежности системы.
- Изображения в трехмерных элементах - вокселях, не в пикселях, что доставляет дополнительные сложности разработчикам систем.
Где это применяется: определение повреждений после удара, для поиска опухоли в мозгу, в кардиологии для определения того, как работает сердце.

Вот пример для определения объема плаценты.
Автоматически это работает хорошо, но не настолько, чтобы это было выпущено в производство, поэтому пока только начинается. Есть несколько стартапов для создания таких систем медицинского зрения. Вообще в deep learning очень много стартапов в ближайшее время. Говорят, что venture capitalists в последние полгода выделили больше бюджета на стартапы обрасти deep learning, чем за прошедшие 5 лет.
Эта область активно развивается, много интересных направлений. Мы с вами живем в интересное время. Если вы занимаетесь deep learning, то вам, наверное, пора открывать свой стартап.
Ну на этом я, наверное, закруглюсь. Спасибо вам большое.
Нейронные сети
Схема простой нейросети. Зелёным обозначены входные элементы, жёлтым - выходной элемент
Иску́сственные нейро́нные се́ти (ИНС) - математические модели, а также их программные или аппаратные реализации, построенные по принципу организации и функционирования биологических нейронных сетей - сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге при мышлении , и при попытке смоделировать эти процессы. Первой такой моделью мозга был перцептрон . Впоследствии эти модели стали использовать в практических целях, как правило в задачах прогнозирования .
Нейронные сети не программируются в привычном смысле этого слова, они обучаются . Возможность обучения - одно из главных преимуществ нейронных сетей перед традиционными алгоритмами. Технически обучение заключается в нахождении коэффициентов связей между нейронами. В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными данными и выходными, а также выполнять обобщение. Это значит, что, в случае успешного обучения, сеть сможет вернуть верный результат на основании данных, которые отсутствовали в обучающей выборке.
Хронология
Известные применения
Кластеризация
Под кластеризацией понимается разбиение множества входных сигналов на классы, при том, что ни количество, ни признаки классов заранее неизвестны. После обучения такая сеть способна определять, к какому классу относится входной сигнал. Сеть также может сигнализировать о том, что входной сигнал не относится ни к одному из выделенных классов - это является признаком новых, отсутствующих в обучающей выборке, данных. Таким образом, подобная сеть может выявлять новые, неизвестные ранее классы сигналов . Соответствие между классами, выделенными сетью, и классами, существующими в предметной области, устанавливается человеком. Кластеризацию осуществляют, например, нейронные сети Кохонена .
Экспериментальный подбор характеристик сети
После выбора общей структуры нужно экспериментально подобрать параметры сети. Для сетей, подобных перцептрону, это будет число слоев, число блоков в скрытых слоях (для сетей Ворда), наличие или отсутствие обходных соединений, передаточные функции нейронов. При выборе количества слоев и нейронов в них следует исходить из того, что способности сети к обобщению тем выше, чем больше суммарное число связей между нейронами . С другой стороны, число связей ограничено сверху количеством записей в обучающих данных.
Экспериментальный подбор параметров обучения
После выбора конкретной топологии, необходимо выбрать параметры обучения нейронной сети. Этот этап особенно важен для сетей, обучающихся с учителем . От правильного выбора параметров зависит не только то, насколько быстро ответы сети будут сходиться к правильным ответам. Например, выбор низкой скорости обучения увеличит время схождения, однако иногда позволяет избежать паралича сети. Увеличение момента обучения может привести как к увеличению, так и к уменьшению времени сходимости, в зависимости от формы поверхности ошибки. Исходя из такого противоречивого влияния параметров, можно сделать вывод, что их значения нужно выбирать экспериментально, руководствуясь при этом критерием завершения обучения (например, минимизация ошибки или ограничение по времени обучения).
Собственно обучение сети
В процессе обучения сеть в определенном порядке просматривает обучающую выборку. Порядок просмотра может быть последовательным, случайным и т. д. Некоторые сети, обучающиеся без учителя , например, сети Хопфилда просматривают выборку только один раз. Другие, например, сети Кохонена , а также сети, обучающиеся с учителем, просматривают выборку множество раз, при этом один полный проход по выборке называется эпохой обучения . При обучении с учителем набор исходных данных делят на две части - собственно обучающую выборку и тестовые данные; принцип разделения может быть произвольным. Обучающие данные подаются сети для обучения, а проверочные используются для расчета ошибки сети (проверочные данные никогда для обучения сети не применяются). Таким образом, если на проверочных данных ошибка уменьшается, то сеть действительно выполняет обобщение. Если ошибка на обучающих данных продолжает уменьшаться, а ошибка на тестовых данных увеличивается, значит, сеть перестала выполнять обобщение и просто «запоминает» обучающие данные. Это явление называется переобучением сети или оверфиттингом . В таких случаях обучение обычно прекращают. В процессе обучения могут проявиться другие проблемы, такие как паралич или попадание сети в локальный минимум поверхности ошибок. Невозможно заранее предсказать проявление той или иной проблемы, равно как и дать однозначные рекомендации к их разрешению.
Проверка адекватности обучения
Даже в случае успешного, на первый взгляд, обучения сеть не всегда обучается именно тому, чего от неё хотел создатель. Известен случай, когда сеть обучалась распознаванию изображений танков по фотографиям, однако позднее выяснилось, что все танки были сфотографированы на одном и том же фоне. В результате сеть «научилась» распознавать этот тип ландшафта, вместо того, чтобы «научиться» распознавать танки . Таким образом, сеть «понимает» не то, что от неё требовалось, а то, что проще всего обобщить.
Классификация по типу входной информации
- Аналоговые нейронные сети (используют информацию в форме действительных чисел);
- Двоичные нейронные сети (оперируют с информацией, представленной в двоичном виде).
Классификация по характеру обучения
- Обучение с учителем - выходное пространство решений нейронной сети известно;
- Обучение без учителя - нейронная сеть формирует выходное пространство решений только на основе входных воздействий. Такие сети называют самоорганизующимися;
- Обучение с подкреплением - система назначения штрафов и поощрений от среды.
Классификация по характеру настройки синапсов
Классификация по времени передачи сигнала
В ряде нейронных сетей активирующая функция может зависеть не только от весовых коэффициентов связей w i j , но и от времени передачи импульса (сигнала) по каналам связи τ i j . По этому в общем виде активирующая (передающая) функция связи c i j от элемента u i к элементу u j имеет вид: . Тогда синхронной сетью i j каждой связи равна либо нулю, либо фиксированной постоянной τ . Асинхронной называют такую сеть у которой время передачи τ i j для каждой связи между элементами u i и u j свое, но тоже постоянное.
Классификация по характеру связей
Сети прямого распространения (Feedforward)
Все связи направлены строго от входных нейронов к выходным. Примерами таких сетей являются перцептрон Розенблатта , многослойный перцептрон , сети Ворда .
Рекуррентные нейронные сети
Сигнал с выходных нейронов или нейронов скрытого слоя частично передается обратно на входы нейронов входного слоя (обратная связь). Рекуррентная сеть сеть Хопфилда «фильтрует» входные данные, возвращаясь к устойчивому состоянию и, таким образом, позволяет решать задачи компрессии данных и построения ассоциативной памяти . Частным случаем рекуррентных сетей является двунаправленные сети. В таких сетях между слоями существуют связи как в направлении от входного слоя к выходному, так и в обратном. Классическим примером является Нейронная сеть Коско .
Радиально-базисные функции
Искусственные нейронные сети, использующие в качестве активационных функций радиально-базисные (такие сети сокращённо называются RBF-сетями). Общий вид радиально-базисной функции:
 , например,
, например, ![]()
где x - вектор входных сигналов нейрона, σ - ширина окна функции, φ(y ) - убывающая функция (чаще всего, равная нулю вне некоторого отрезка).
Радиально-базисная сеть характеризуется тремя особенностями:
1. Единственный скрытый слой
2. Только нейроны скрытого слоя имеют нелинейную активационную функцию
3. Синаптические веса связей входного и скрытого слоев равны единице
Про процедуру обучения - см. литературу
Самоорганизующиеся карты
Такие сети представляют собой соревновательную нейронную сеть с обучением без учителя , выполняющую задачу визуализации и кластеризации . Является методом проецирования многомерного пространства в пространство с более низкой размерностью (чаще всего, двумерное), применяется также для решения задач моделирования, прогнозирования и др. Является одной из версий нейронных сетей Кохонена . Самоорганизующиеся карты Кохонена служат, в первую очередь, для визуализации и первоначального («разведывательного») анализа данных .
Сигнал в сеть Кохонена поступает сразу на все нейроны, веса соответствующих синапсов интерпретируются как координаты положения узла, и выходной сигнал формируется по принципу «победитель забирает всё» - то есть ненулевой выходной сигнал имеет нейрон, ближайший (в смысле весов синапсов) к подаваемому на вход объекту. В процессе обучения веса синапсов настраиваются таким образом, чтобы узлы решетки «располагались» в местах локальных сгущений данных, то есть описывали кластерную структуру облака данных, с другой стороны, связи между нейронами соответствуют отношениям соседства между соответствующими кластерами в пространстве признаков.
Удобно рассматривать такие карты как двумерные сетки узлов, размещенных в многомерном пространстве. Изначально самоорганизующаяся карта представляет из себя сетку из узлов, соединенный между собой связями. Кохонен рассматривал два варианта соединения узлов - в прямоугольную и гексагональную сетку - отличие состоит в том, что в прямоугольной сетке каждый узел соединен с 4-мя соседними, а в гексагональной - с 6-ю ближайщими узлами. Для двух таких сеток процесс построения сети Кохонена отличается лишь в том месте, где перебираются ближайшие к данному узлу соседи.
Начальное вложение сетки в пространство данных выбирается произвольным образом. В авторском пакете SOM_PAK предлагаются варианты случайного начального расположения узлов в пространстве и вариант расположения узлов в плоскости. После этого узлы начинают перемещаться в пространстве согласно следующему алгоритму:
- Случайным образом выбирается точка данных x .
- Определяется ближайший к x узел карты (BMU - Best Matching Unit).
- Этот узел перемещается на заданный шаг по направлению к x. Однако, он перемещается не один, а увлекает за собой определенное количество ближайших узлов из некоторой окрестности на карте. Из всех двигающихся узлов наиболее сильно смещается центральный - ближайший к точке данных - узел, а остальные испытывают тем меньшие смещения, чем дальше они от BMU. В настройке карты различают два этапа - этап грубой (ordering) и этап тонкой (fine-tuning) настройки. На первом этапе выбираются большие значения окрестностей и движение узлов носит коллективный характер - в результате карта «расправляется» и грубым образом отражает структуру данных; на этапе тонкой настройки радиус окрестности равен 1-2 и настраиваются уже индивидуальные положения узлов. Кроме этого, величина смещения равномерно затухает со временем, то есть она велика в начале каждого из этапов обучения и близка к нулю в конце.
- Алгоритм повторяется определенное число эпох (понятно, что число шагов может сильно изменяться в зависимости от задачи).
Известные типы сетей
- Сеть Хэмминга;
- Неокогнитрон;
- Хаотическая нейронная сеть;
- Сеть встречного распространения;
- Сеть радиальных базисных функций (RBF-сеть);
- Сеть обобщенной регрессии;
- Вероятностная сеть;
- Сиамская нейронная сеть;
- Сети адаптивного резонанса.
Отличия от машин с архитектурой фон Неймана
Длительный период эволюции придал мозгу человека много качеств, которые отсутствуют в машинах с архитектурой фон Неймана:
- Массовый параллелизм;
- Распределённое представление информации и вычисления;
- Способность к обучению и обобщению;
- Адаптивность;
- Свойство контекстуальной обработки информации;
- Толерантность к ошибкам;
- Низкое энергопотребление.
Нейронные сети - универсальные аппроксиматоры
Нейронные сети - универсальные аппроксимирующие устройства и могут с любой точностью имитировать любой непрерывный автомат. Доказана обобщённая аппроксимационная теорема : с помощью линейных операций и каскадного соединения можно из произвольного нелинейного элемента получить устройство, вычисляющее любую непрерывную функцию с любой наперёд заданной точностью . Это означает, что нелинейная характеристика нейрона может быть произвольной: от сигмоидальной до произвольного волнового пакета или вейвлета , синуса или полинома . От выбора нелинейной функции может зависеть сложность конкретной сети, но с любой нелинейностью сеть остаётся универсальным аппроксиматором и при правильном выборе структуры может сколь угодно точно аппроксимировать функционирование любого непрерывного автомата.
Примеры приложений
Предсказание финансовых временных рядов
Входные данные - курс акций за год. Задача - определить завтрашний курс. Проводится следующее преобразование - выстраивается в ряд курс за сегодня, вчера, за позавчера, за позапозавчера. Следующий ряд - смещается по дате на один день и так далее. На полученном наборе обучается сеть с 3 входами и одним выходом - то есть выход: курс на дату, входы: курс на дату минус 1 день, минус 2 дня, минус 3 дня. Обученной сети подаем на вход курс за сегодня, вчера, позавчера и получаем ответ на завтра. Нетрудно заметить, что в этом случае сеть просто выведет зависимость одного параметра от трёх предыдущих. Если желательно учитывать ещё какой-то параметр (например, общий индекс по отрасли), то его надо добавить как вход (и включить в примеры), переобучить сеть и получить новые результаты. Для наиболее точного обучения стоит использовать метод ОРО , как наиболее предсказуемый и несложный в реализации.
Психодиагностика
Серия работ М. Г. Доррера с соавторами посвящена исследованию вопроса о возможности развития психологической интуиции у нейросетевых экспертных систем . Полученные результаты дают подход к раскрытию механизма интуиции нейронных сетей, проявляющейся при решении ими психодиагностических задач. Создан нестандартный для компьютерных методик интуитивный подход к психодиагностике , заключающийся в исключении построения описанной реальности . Он позволяет сократить и упростить работу над психодиагностическими методиками.
Хемоинформатика
Нейронные сети широко используются в химических и биохимических исследованиях В настоящее время нейронные сети являются одним из самых распространенных методов хемоинформатики для поиска количественных соотношений структура-свойство , благодаря чему они активно используются как для прогнозирования физико-химических свойств и биологической активности химических соединений, так и для направленного дизайна химических соединений и материалов с заранее заданными свойствами, в том числе при разработке новых лекарственных препаратов.
Примечания
- Мак-Каллок У. С., Питтс В. ,Логическое исчисление идей, относящихся к нервной активности // В сб.: «Автоматы» под ред. К. Э. Шеннона и Дж. Маккарти. - М.: Изд-во иностр. лит., 1956. - с.363-384. (Перевод английской статьи 1943 г.)
- Pattern Recognition and Adaptive Control. BERNARD WIDROW
- Уидроу Б., Стирнс С. , Адаптивная обработка сигналов. - М.: Радио и связь, 1989. - 440 c.
- Werbos P. J. , Beyond regression: New tools for prediction and analysis in the behavioral sciences. Ph.D. thesis, Harvard University, Cambridge, MA, 1974.
- Галушкин А. И. Синтез многослойных систем распознавания образов. - М.: «Энергия», 1974.
- Rumelhart D.E., Hinton G.E., Williams R.J. , Learning Internal Representations by Error Propagation. In: Parallel Distributed Processing, vol. 1, pp. 318-362. Cambridge, MA, MIT Press. 1986.
- Барцев С. И., Охонин В. А. Адаптивные сети обработки информации. Красноярск: Ин-т физики СО АН СССР, 1986. Препринт N 59Б. - 20 с.
- BaseGroup Labs - Практическое применение нейросетей в задачах классификации
- Такой вид кодирования иногда называют кодом «1 из N»
- Открытые системы - введение в нейросети
- Миркес Е. М. ,Логически прозрачные нейронные сети и производство явных знаний из данных , В кн.: Нейроинформатика / А. Н. Горбань, В. Л. Дунин-Барковский, А. Н. Кирдин и др. - Новосибирск: Наука. Сибирское предприятие РАН, 1998. - 296 с ISBN 5020314102
- Упоминание этой истории в журнале «Популярная механика»
- http://www.intuit.ru/department/expert/neuro/10/ INTUIT.ru - Рекуррентные сети как ассоциативные запоминающие устройства]
- Kohonen, T. (1989/1997/2001), Self-Organizing Maps, Berlin - New York: Springer-Verlag. First edition 1989, second edition 1997, third extended edition 2001, ISBN 0-387-51387-6, ISBN 3-540-67921-9
- Зиновьев А. Ю. Визуализация многомерных данных . - Красноярск: Изд. Красноярского государственного технического университета, 2000. - 180 с.
- Горбань А. Н. , Обобщенная аппроксимационная теорема и вычислительные возможности нейронных сетей , Сибирский журнал вычислительной математики, 1998. Т.1, № 1. С. 12-24.
- Gorban A.N., Rossiyev D.A., Dorrer M.G. , MultiNeuron - Neural Networks Simulator For Medical, Physiological, and Psychological Applications , Wcnn’95, Washington, D.C.: World Congress on Neural Networks 1995 International Neural Network Society Annual Meeting: Renaissance Hotel, Washington, D.C., USA, July 17-21, 1995.
- Доррер М. Г. , Психологическая интуиция искусственных нейронных сетей , Дисс. ... 1998. Другие копии онлайн: ,
- Баскин И. И., Палюлин В. А., Зефиров Н. С., Применение искусственных нейронных сетей в химических и биохимических исследованиях, Вестн. Моск. Ун-Та. Сер. 2. Химия. 1999. Т.40. № 5.
- Гальберштам Н. М., Баскин И. И., Палюлин В. А., Зефиров Н. С. Нейронные сети как метод поиска зависимостей структура – свойство органических соединений // Успехи химии . - 2003. - Т. 72. - № 7. - С. 706-727.
- Баскин И. И., Палюлин В. А., Зефиров Н. С. Многослойные персептроны в исследовании зависимостей «структура-свойство» для органических соединений // Российский химический журнал (Журнал Российского химического общества им. Д.И.Менделеева) . - 2006. - Т. 50. - С. 86-96.
Ссылки
- Artificial Neural Network for PHP 5.x - Серьезный проект по разработке нейронных сетей на языке программирования PHP 5.X
- Форум, посвященный Нейронным Сетям и Генетическим Алгоритмам
- Миркес Е. М. ,
В этот раз я решил изучить нейронные сети. Базовые навыки в этом вопросе я смог получить за лето и осень 2015 года. Под базовыми навыками я имею в виду, что могу сам создать простую нейронную сеть с нуля. Примеры можете найти в моих репозиториях на GitHub. В этой статье я дам несколько разъяснений и поделюсь ресурсами, которые могут пригодиться вам для изучения.
Шаг 1. Нейроны и метод прямого распространения
Так что же такое «нейронная сеть»? Давайте подождём с этим и сперва разберёмся с одним нейроном.
Нейрон похож на функцию: он принимает на вход несколько значений и возвращает одно.
Круг ниже обозначает искусственный нейрон. Он получает 5 и возвращает 1. Ввод - это сумма трёх соединённых с нейроном синапсов (три стрелки слева).
В левой части картинки мы видим 2 входных значения (зелёного цвета) и смещение (выделено коричневым цветом).
Входные данные могут быть численными представлениями двух разных свойств. Например, при создании спам-фильтра они могли бы означать наличие более чем одного слова, написанного ЗАГЛАВНЫМИ БУКВАМИ, и наличие слова «виагра».
Входные значения умножаются на свои так называемые «веса», 7 и 3 (выделено синим).
Теперь мы складываем полученные значения со смещением и получаем число, в нашем случае 5 (выделено красным). Это - ввод нашего искусственного нейрона.

Потом нейрон производит какое-то вычисление и выдает выходное значение. Мы получили 1, т.к. округлённое значение сигмоиды в точке 5 равно 1 (более подробно об этой функции поговорим позже).
Если бы это был спам-фильтр, факт вывода 1 означал бы то, что текст был помечен нейроном как спам.

Иллюстрация нейронной сети с Википедии.
Если вы объедините эти нейроны, то получите прямо распространяющуюся нейронную сеть - процесс идёт от ввода к выводу, через нейроны, соединённые синапсами, как на картинке слева.
Шаг 2. Сигмоида
После того, как вы посмотрели уроки от Welch Labs, хорошей идеей было бы ознакомиться с четвертой неделей курса по машинному обучению от Coursera , посвящённой нейронным сетям - она поможет разобраться в принципах их работы. Курс сильно углубляется в математику и основан на Octave, а я предпочитаю Python. Из-за этого я пропустил упражнения и почерпнул все необходимые знания из видео.

Сигмоида просто-напросто отображает ваше значение (по горизонтальной оси) на отрезок от 0 до 1.
Первоочередной задачей для меня стало изучение сигмоиды , так как она фигурировала во многих аспектах нейронных сетей. Что-то о ней я уже знал из третьей недели вышеупомянутого курса , поэтому я пересмотрел видео оттуда.
Но на одних видео далеко не уедешь. Для полного понимания я решил закодить её самостоятельно. Поэтому я начал писать реализацию алгоритма логистической регрессии (который использует сигмоиду).
Это заняло целый день, и вряд ли результат получился удовлетворительным. Но это неважно, ведь я разобрался, как всё работает. Код можно увидеть .
Вам необязательно делать это самим, поскольку тут требуются специальные знания - главное, чтобы вы поняли, как устроена сигмоида.
Шаг 3. Метод обратного распространения ошибки
Понять принцип работы нейронной сети от ввода до вывода не так уж и сложно. Гораздо сложнее понять, как нейронная сеть обучается на наборах данных. Использованный мной принцип называется







